AI 配置说明
FastGPT AI 配置说明
AI 配置用于调整应用或工作流中 AI 对话节点的模型、回复长度、多模态识别、回复格式和思考展示等行为。本文主要介绍配置弹窗中的各项含义,以及常见场景下的选择方式。
配置入口
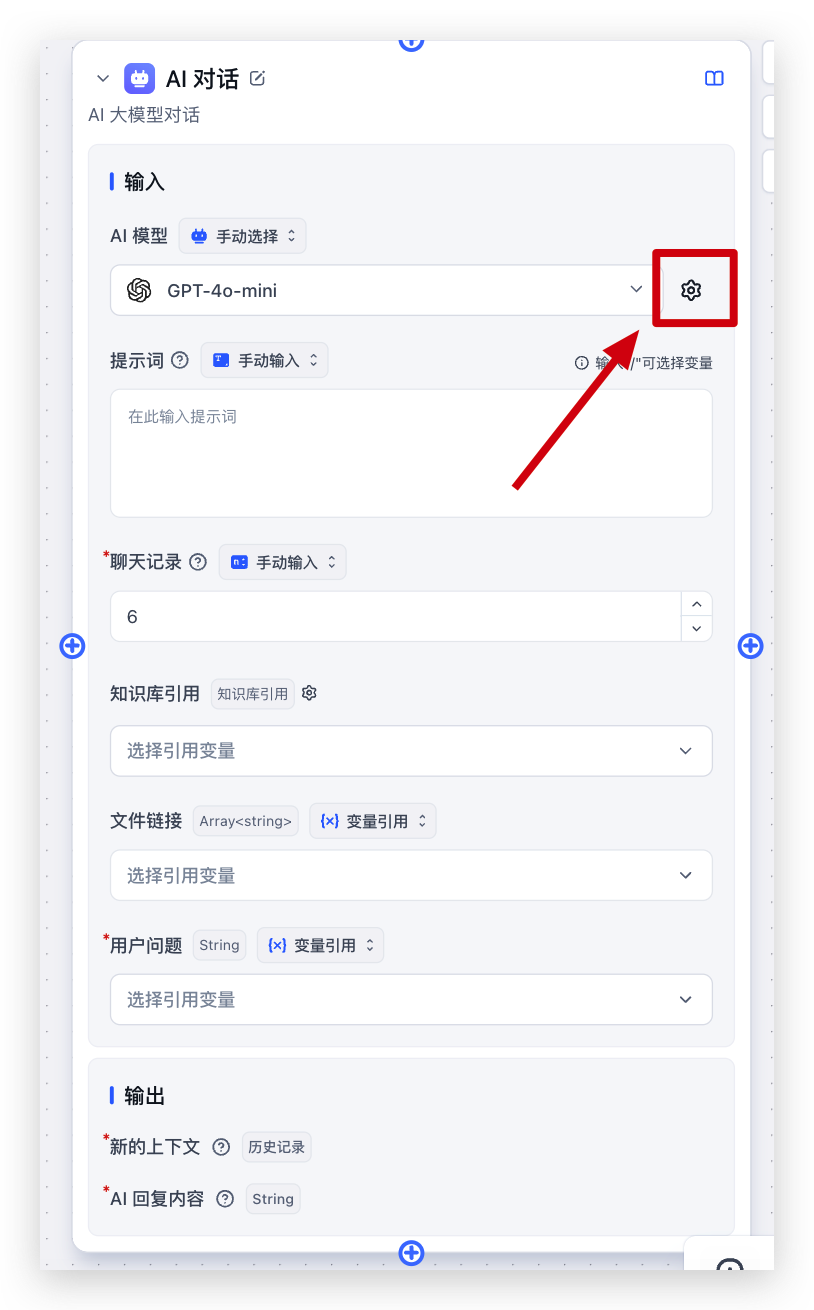
在应用编辑页中,找到 AI 配置 区域,选择 AI 模型后,点击模型选择框右侧的设置按钮,即可打开 AI 配置弹窗。
在工作流中,点击 AI 对话 节点的 AI 模型配置项,也可以通过右侧设置按钮打开同一个配置弹窗。
如果暂时没有特殊要求,通常只需要选择合适的 AI 模型,其他参数保持默认即可。
 |  |  |
配置会不会都显示?
不会。弹窗会根据当前模型的能力显示可用配置。例如,模型不支持多模态识别时,不会提供多模态识别选项;模型不支持思考配置时,也不会显示对应选项。
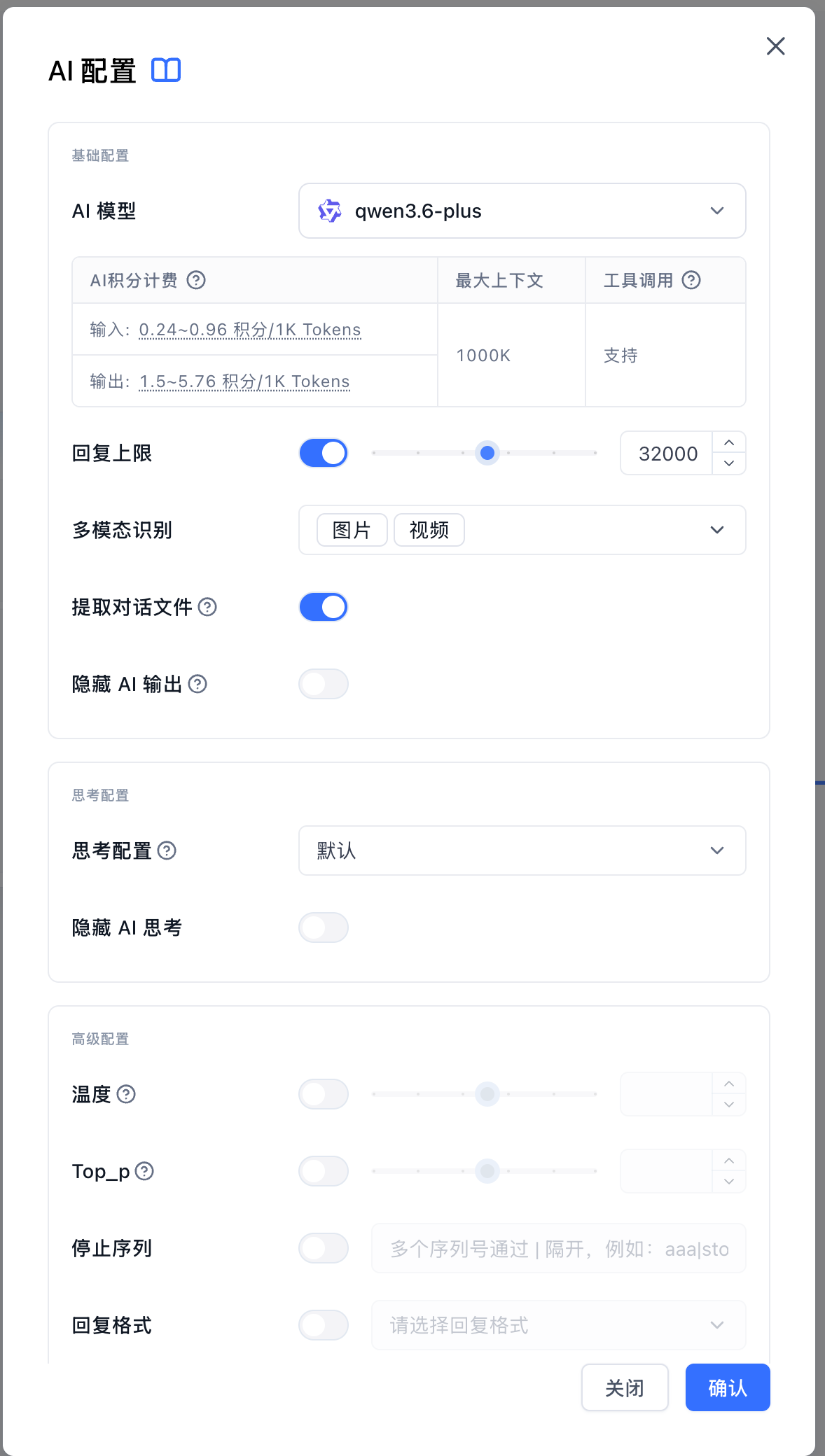
基础配置
AI 模型
用于选择当前应用或节点使用的 AI 模型。不同模型在回答能力、价格、可处理内容长度、工具调用能力、多模态能力等方面会有差异。
模型下面会显示几类信息:
- 积分价格:模型调用时的积分消耗参考,通常会区分输入内容和模型回复。
- 最大上下文:模型单次请求可参考的内容长度。数值越大,越适合长文档、长对话等场景。
- 工具调用:如果显示支持,说明该模型可以配合应用中选择的工具完成查询、计算或外部能力调用。
- 多模态能力:如果模型支持图片、音频或视频输入,可以在 AI 配置中开启对应的多模态识别能力。不同模型支持的媒体类型可能不同,具体以配置弹窗中显示的能力为准。
记忆轮数
控制 AI 回答时最多参考前面多少轮聊天。
数值越大,AI 越容易参考更早的对话,但也会带入更多内容,可能增加消耗并影响响应速度。数值过小,则可能无法利用前文信息。
如果没有明确需求,建议先使用默认值。客服、知识库问答类应用通常保留少量历史轮数即可。
回复上限
控制 AI 一次最多回答多长。
打开后,可以通过滑块限制模型回复长度。设置过低时,回复可能被提前截断;设置较高时,模型可以生成更完整的内容,但也可能增加消耗。
如果希望回答简短,可以适当调低;如果需要生成方案、文章或较长说明,可以适当调高。
温度
控制回答的稳定程度。
数值较低时,回答更稳定,更适合客服、知识库问答、规则明确的场景。数值较高时,回答更发散,更适合写作、头脑风暴、创意内容等场景。
常见选择:
- 客服、知识库问答:建议偏低。
- 文案、故事、创意建议:可以适当调高。
- 不确定时:建议保持默认。
Top_p
Top_p 也是控制回复随机性的参数,作用和温度有一定重叠。
通常不建议同时调整温度和 Top_p。如果已经通过温度获得了期望效果,可以保持 Top_p 关闭或默认。
停止序列
当 AI 回复中出现指定内容时,会停止继续输出。
普通聊天一般不需要设置。只有在需要模型输出到某个固定标记就结束时才使用。多个停止词可以用 | 分隔,例如:结束|stop。
回复格式
控制 AI 的回答格式。
普通聊天、客服问答、知识库问答通常保持默认即可。只有当后续流程需要读取固定格式的内容时,才需要修改该配置。
如果选择 json_schema,还需要填写对应的格式要求。该选项适合需要模型按固定结构返回内容的场景。
多模态识别
如果当前模型配置了多模态能力,这里可以控制 AI 是否读取用户输入中的图片、音频或视频内容。
可选择的类型取决于模型本身的能力。模型只支持图片时,只能开启图片识别;模型同时支持图片、音频或视频时,可以按需选择对应类型。
打开后,AI 对话节点会在请求模型前,将用户上传的对应类型文件,或用户问题中的对应媒体链接,转换为模型可识别的输入。例如:
- 图片识别:用于识别截图、表格图片、商品图、海报等图片内容。
- 音频识别:用于让支持音频输入的模型理解用户上传的音频内容。
- 视频识别:用于让支持视频输入的模型理解用户上传的视频内容。
需要注意:
- 即使开启了某类识别,请求发送前也会再次根据模型能力过滤,不支持的类型不会发送给模型。
- 用户问题中的媒体链接需要开启“提取链接中的多模态文件”后才会尝试解析。当前仅在用户问题少于 500 字时尝试提取,且一次最多处理 4 个媒体链接。
- 普通文档文件不会作为多模态输入直接发送给 LLM,文档内容仍需要通过文件解析转成文本。
- 多模态识别依赖模型本身能力。如果弹窗里显示“该模型不支持多模态识别”,需要换成支持对应多模态输入的模型。
隐藏 AI 输出
打开后,AI 生成的内容不会直接展示给用户,但仍然可以通过 AI 回复输出交给后续节点继续处理。例如先让 AI 整理内部结果,再由下一个节点改写成最终回复。
思考配置
部分模型支持先生成思考过程,再输出最终回答。选择这类模型时,弹窗会显示思考配置。
思考配置
用于控制模型的思考强度。
- 默认:使用模型默认配置。
- 不思考:尽量直接回答,适合简单问题。
- 极简思考 / 轻量思考 / 标准思考 / 深度思考 / 极致思考:问题越复杂,可以选择更高的思考强度。
思考强度配置对齐 OpenAI 规范中的 reasoning_effort,并通过 ai-proxy 适配不同模型平台的参数格式。完整规则可参考 ai-proxy reasoning compatibility。
OpenAI 兼容枚举与默认 budget 映射
| FastGPT 选项 | OpenAI 兼容值 | 默认 budget |
|---|---|---|
| 默认 | 不显式传递 reasoning_effort | 使用模型默认值 |
| 不思考 | none | 0 |
| 极简思考 | minimal | 1024 |
| 轻量思考 | low | 2048 |
| 标准思考 | medium | 8192 |
| 深度思考 | high | 16384 |
| 极致思考 | xhigh | 32768 |
如果某个平台只支持 token budget,不支持离散档位,ai-proxy 会按上表把 effort 转成 budget。反向归一化时,<=0 会被视为 none,1~1024 视为 minimal,1025~4096 视为 low,4097~12288 视为 medium,12289~24576 视为 high,更高则视为 xhigh。
OpenAI / OpenAI Responses
| 目标格式 | 写入字段 | 映射方式 |
|---|---|---|
| OpenAI Chat / Completions | reasoning_effort | none/minimal/low/medium/high/xhigh 原样写入 |
| OpenAI Responses | reasoning.effort | none/minimal/low/medium/high/xhigh 原样写入 |
OpenAI Chat / Completions 模式只解析 reasoning_effort。当 Gemini、Claude 等请求被转换为 OpenAI 兼容格式时,也会先归一化为该字段。
Google Gemini
Gemini 原生请求会从 generationConfig.thinkingConfig 中解析 thinkingLevel、thinkingBudget 和 includeThoughts。写给 Gemini 上游时,ai-proxy 会根据模型系列选择 thinkingLevel 或 thinkingBudget。
| OpenAI 兼容值 | Gemini 3+ Pro | Gemini 3+ 非 Pro | gemini-2.5-pro | gemini-2.5-flash | gemini-2.5-flash-lite |
|---|---|---|---|---|---|
none | thinkingLevel=low | thinkingLevel=minimal | thinkingBudget=128 | thinkingBudget=0 | thinkingBudget=0 |
minimal | thinkingLevel=low | thinkingLevel=minimal | thinkingBudget=1024 | thinkingBudget=1024 | thinkingBudget=1024 |
low | thinkingLevel=low | thinkingLevel=low | thinkingBudget=2048 | thinkingBudget=2048 | thinkingBudget=2048 |
medium | thinkingLevel=low | thinkingLevel=medium | thinkingBudget=8192 | thinkingBudget=8192 | thinkingBudget=8192 |
high | thinkingLevel=high | thinkingLevel=high | thinkingBudget=16384 | thinkingBudget=16384 | thinkingBudget=16384 |
xhigh | thinkingLevel=high | thinkingLevel=high | thinkingBudget=32768 | thinkingBudget=24576 | thinkingBudget=24576 |
Gemini 2.5 系列会按模型允许范围 clamp budget。部分 Gemini 模型不能真正关闭 thinking,none 会退化为模型允许的最小 level 或 budget。
Claude / Anthropic / Bedrock / Vertex AI
Claude 原生请求会解析 thinking 和 output_config。写给 Anthropic 官方、AWS Bedrock Claude 或 Vertex AI Claude 时,字段形态仍遵循 Claude 的 thinking 规则。
| OpenAI 兼容值 | 旧式 / budget 模式 | adaptive 模式 |
|---|---|---|
none | thinking.type=disabled | thinking.type=disabled,部分 adaptive-only 模型可能移除该字段 |
minimal | thinking.type=enabled , budget_tokens=1024 | thinking.type=adaptive , output_config.effort=low |
low | thinking.type=enabled , budget_tokens=2048 | thinking.type=adaptive , output_config.effort=low |
medium | thinking.type=enabled , budget_tokens=8192 | thinking.type=adaptive , output_config.effort=medium |
high | thinking.type=enabled , budget_tokens=16384 | thinking.type=adaptive , output_config.effort=high |
xhigh | thinking.type=enabled , budget_tokens=32768 | thinking.type=adaptive , output_config.effort=max |
budget 模式会保证 budget_tokens < max_tokens,并把过小的 budget 提升到上游可接受的最小值。
Ali DashScope / Qwen / QwQ / GLM / Kimi 兼容模型
| OpenAI 兼容值 | 支持 thinking_budget 的模型 | 不支持 budget 的模型 |
|---|---|---|
none | enable_thinking=false,移除 thinking_budget | enable_thinking=false |
minimal | enable_thinking=true , thinking_budget=1024 | enable_thinking=true |
low | enable_thinking=true , thinking_budget=2048 | enable_thinking=true |
medium | enable_thinking=true , thinking_budget=8192 | enable_thinking=true |
high | enable_thinking=true , thinking_budget=16384 | enable_thinking=true |
xhigh | enable_thinking=true , thinking_budget=32768 | enable_thinking=true |
当前 ai-proxy 会把 qwen3-*、qwq-*、模型名包含 glm 或 kimi 的 Ali-compatible 模型视为支持 thinking_budget。qwen3-* 非流式请求会被强制关闭 thinking,qwq-* 请求会被强制改为流式。
Zhipu / DeepSeek / Doubao / Moonshot Kimi
这些平台当前主要保留开关语义,不保留 budget 或细粒度 effort。
| 平台 | OpenAI 兼容值 | 写给上游的字段 |
|---|---|---|
| Zhipu / DeepSeek / Doubao | none | thinking.type=disabled |
| Zhipu / DeepSeek / Doubao | minimal/low/medium/high/xhigh | thinking.type=enabled |
| Moonshot / Kimi 支持开关的模型 | none | thinking.type=disabled,并移除 reasoning_effort |
| Moonshot / Kimi 支持开关的模型 | minimal/low/medium/high/xhigh | thinking.type=enabled,并移除 reasoning_effort |
| Moonshot / Kimi 不支持开关的模型 | 任意值 | 移除 reasoning_effort,不发送 thinking |
Moonshot / Kimi 是否能写入 thinking.type 取决于渠道映射后的实际上游模型名。
部分模型不一定完全支持所有思考选项。如果切换后出现报错,可以改回默认选项。
隐藏 AI 思考
打开后,用户只会看到最终回答,看不到 AI 的思考过程。调试应用时,可以临时关闭该开关,观察模型的中间思考内容。