知识库
常见问题
知识库常见问题
文件解析失败
未打开 PDF 增强解析。如果在上传文件设置参数时,没有打开【PDF 增强解析】设置时,需要在 Admin 后台正确配置 OCR 模块以支持增强解析。
文件中文乱码
将文件另存为 UTF-8 编码格式。
文件处理模型与索引模型
- 文件处理模型:用于数据处理的【增强处理】和【问答拆分】。在【增强处理】中,生成相关问题和摘要,在【问答拆分】中执行问答对生成。
- 索引模型:用于向量化,即通过对文本数据进行处理和组织,构建出一个能够快速查询的数据结构。
Excel 文件导入
xlsx 等都可以上传的,不止支持 CSV。
Tokens 计算方式
统一按 gpt3.5 标准。
恢复重排模型
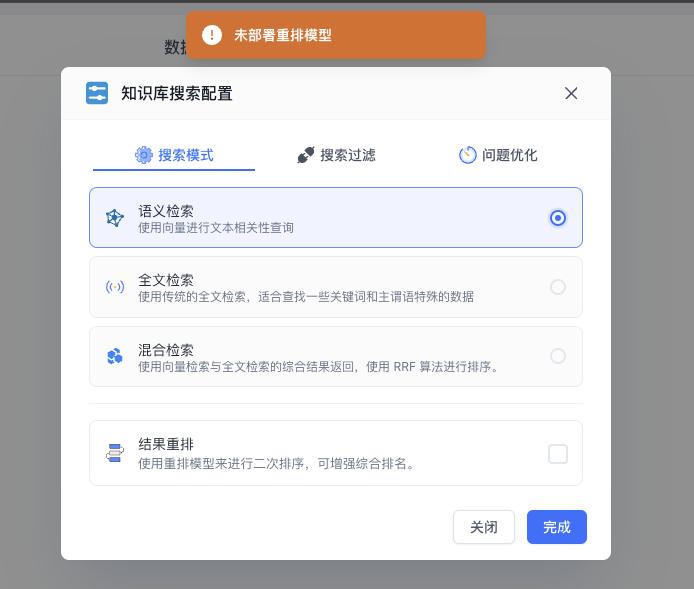
config.json 文件里面配置后就可以勾选重排模型
套餐到期后的数据保留
免费版是三十天不登录后清空知识库,应用不会动。其他付费套餐到期后自动切免费版。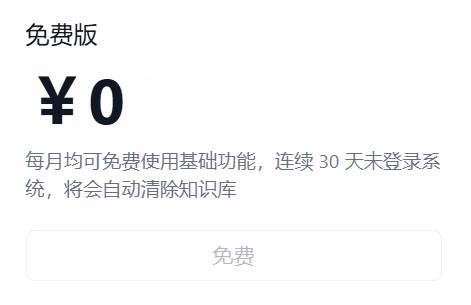
知识库结果过多导致回答中断
FastGPT 回复长度计算公式:
最大回复=min(配置的最大回复(内置的限制),最大上下文(输入和输出的总和)- 历史记录)
18K 模型 ->输入与输出的和
输出增多 ->输入减小
所以可以:
-
检查配置的最大回复(回复上限)
-
减小输入来增大输出,即减小历史记录,在工作流其实也就是“聊天记录”
配置的最大回复:
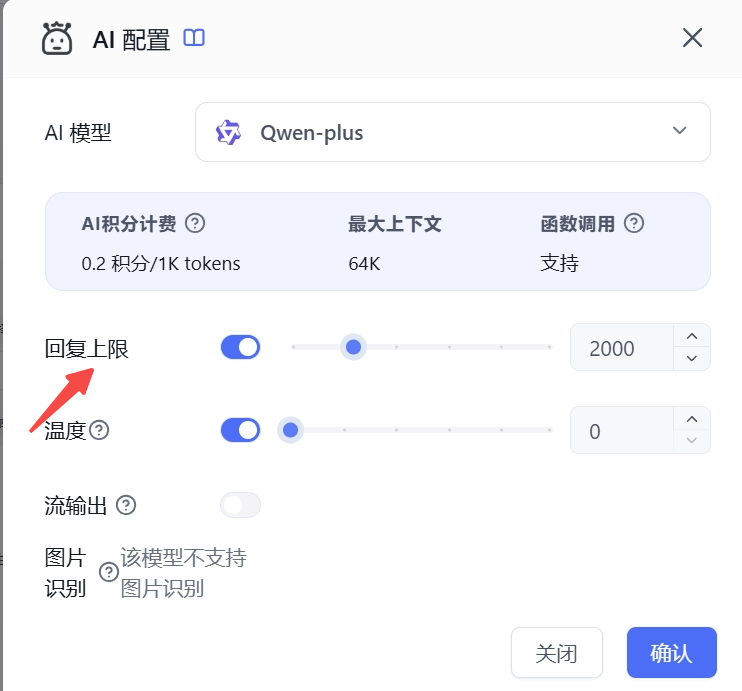
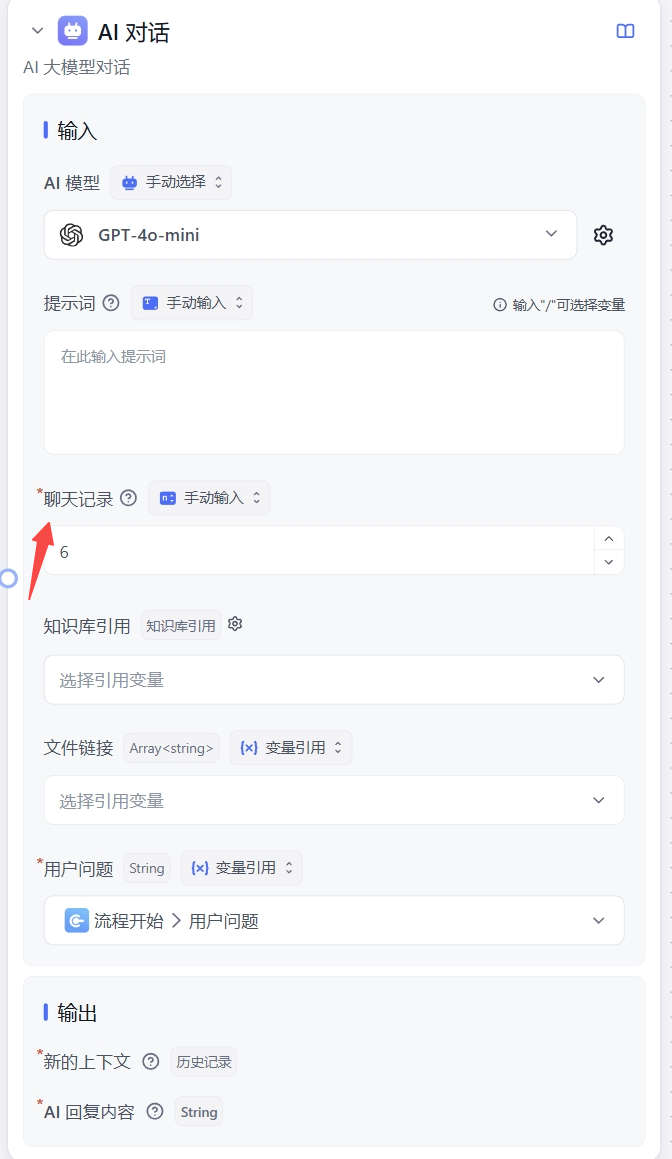
另外私有化部署的时候,后台配模型参数,可以在配置最大上文时,预留一些空间,比如 128000 的模型,可以只配置 120000, 剩余的空间后续会被安排给输出
聊天记录触发上下文限制
FastGPT 回复长度计算公式:
最大回复=min(配置的最大回复(内置的限制),最大上下文(输入和输出的总和)- 历史记录)
18K 模型 ->输入与输出的和
输出增多 ->输入减小
所以可以:
- 检查配置的最大回复(回复上限)
- 减小输入来增大输出,即减小历史记录,在工作流其实也就是“聊天记录”
配置的最大回复:
另外,私有化部署的时候,后台配模型参数,可以在配置最大上文时,预留一些空间,比如 128000 的模型,可以只配置 120000, 剩余的空间后续会被安排给输出。
知识库页面闪烁
未配置索引模型,补齐索引模型配置。